
aiWithWechat可以帮助企业或个人制作微信智能助手。在公司内部或个人电脑上部署一套aiWithWechat,可以成为一个智能助手,关注"企起期"公众号,可以按照指定的问题给出答案,同时也能够在发现问题不匹配的情况下,用文心一言(默认)的大语言模型进行问题回答。有了它,可以实现类似于客服或者助手的功能,感兴趣的话未来还可以集成第三方接口或者公司内部接口衍生出更强大的功能。
文心一言(英文名:ERNIE Bot)是百度全新一代知识增强大语言模型,文心大模型家族的新成员,能够与人对话互动,回答问题,协助创作,高效便捷地帮助人们获取信息、知识和灵感。文心一言是知识增强的大语言模型,基于飞桨深度学习平台和文心知识增强大模型,持续从海量数据和大规模知识中融合学习具备知识增强、检索增强和对话增强的技术特色 [5] [38] [43-44] [46] 。
2023年3月16日,百度开启文心一言邀请测试。 [46] 文心一言从数万亿数据和数千亿知识中融合学习,得到预训练大模型,在此基础上采用有监督精调、人类反馈强化学习、提示等技术,具备知识增强、检索增强和对话增强的技术优势。
2023年5月,百度文心大模型3.5版本已内测可用。 [74] 在基础模型升级、精调技术创新、知识点增强、逻辑推理增强、插件机制等方面创新突破,取得效果和效率的提升。
2023年8月31日,文心一言率先向全社会全面开放。 [76] 9月13日,百度发布文心一言插件生态平台“灵境矩阵”。 [91] 文心一言面向全社会开放至百度世界2023召开,40多天的时间,文心一言用户规模已经达到4500万,开发者5.4万,场景4300个,应用825个,插件超过500个。
2023年10月17日,百度世界2023大会上,李彦宏宣布文心大模型4.0正式发布,开启邀请测试。文心大模型4.0是迄今为止最强大的文心大模型,实现了基础模型的全面升级,在理解、生成、逻辑和记忆能力上都有着显著提升。
试用时,您只需要微信中搜索企起期并关注“企起期”就能进行试用了。请扫描以下二维码关注公众号。

在机器学习和自然语言处理中,embedding是指将高维度的数据(例如文字、图片、音频)映射到低维度空间的过程。embedding向量通常是一个由实数构成的向量,它将输入的数据表示成一个连续的数值空间中的点。
简单来说,embedding就是一个N维的实值向量,它几乎可以用来表示任何事情,如文本、音乐、视频等。在这里,我们也主要是关注文本的embedding。
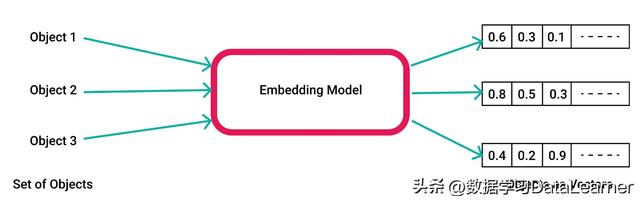
而embedding重要的原因在于它可以表示单词或者语句的语义。实值向量的embedding可以表示单词的语义,主要是因为这些embedding向量是根据单词在语言上下文中的出现模式进行学习的。例如,如果一个单词在一些上下文中经常与另一个单词一起出现,那么这两个单词的嵌入向量在向量空间中就会有相似的位置。这意味着它们有相似的含义和语义。
embedding技术的发展可以追溯到20世纪50年代和60年代的语言学研究,其中最著名的是Harris在1954年提出的分布式语义理论(distributional semantic theory)。这个理论认为,单词的语义可以通过它们在上下文中的分布来表示,也就是说,单词的含义可以从其周围的词语中推断出来。
在计算机科学领域,最早的embedding技术可以追溯到20世纪80年代和90年代的神经网络研究。在那个时候,人们开始尝试使用神经网络来学习单词的embedding表示。其中最著名的是Bengio在2003年提出的神经语言模型(neural language model),它可以根据单词的上下文来预测下一个单词,并且可以使用这个模型来生成单词的embedding表示。
自从2010年左右以来,随着深度学习技术的发展,embedding技术得到了广泛的应用和研究。在这个时期,出现了一些重要的嵌入算法,例如Word2Vec、GloVe和FastText等。这些算法可以通过训练神经网络或使用矩阵分解等技术来学习单词的嵌入表示。这些算法被广泛用于各种自然语言处理任务中,例如文本分类、机器翻译、情感分析等。
近年来,随着深度学习和自然语言处理技术的快速发展,embedding技术得到了进一步的改进和发展。例如,BERT、ELMo和GPT等大型语言模型可以生成上下文相关的embedding表示,这些embedding可以更好地捕捉单词的语义和上下文信息。
Embedding-V1是基于百度文心大模型技术的文本表示模型,将文本转化为用数值表示的向量形式,用于文本检索、信息推荐、知识挖掘等场景。本文介绍了Embedding-V1相关API。
名称 | 类型 | 必填 | 描述 |
access_token | string | 是 | 通过API Key和Secret Key获取的access_token,参考Access Token获取 |
名称 | 类型 | 必填 | 描述 |
input | List(string) | 是 | 输入文本以获取embeddings。说明: |
user_id | string | 否 | 表示最终用户的唯一标识符,可以监视和检测滥用行为,防止接口恶意调用 |
名称 | 类型 | 描述 |
id | string | 本轮对话的id |
object | string | 回包类型,固定值“embedding_list” |
created | int | 时间戳 |
data | List(embedding_data) | embedding信息,data成员数和文本数量保持一致 |
usage | usage | token统计信息,token数 = 汉字数+单词数*1.3 (仅为估算逻辑) |
需要注意的是,目前Embedding-V1版本采用的是384个维度的向量进行表示,而OpenAI的embedding采用的是1536个维度的向量进行表示。理论上,维度越大,占用的计算资源会越多,相应的语义理解会更准确!!!
目前aiWithWechat的公众号版本就是采用的百度文心一言,在国内使用百度的服务,性能上不会有任何问题!而使用OpenAI的服务,则需要进行一些技术处理!
欢迎大家访问www.iqiqiqi.cn网站了解企起期提供的更多服务!!!
扫码关注不迷路!!!
郑州升龙商业广场B座25层
service@iqiqiqi.cn

联系电话:187-0363-0315
联系电话:199-3777-5101





