
aiWithWechat中间层部分是采用Python语言实现,为什么需要弄这么一个中间层呢?因为和AI相关的组件及第三方库基本都是python或者NodeJS提供的,当然也能用java写这些逻辑,但是代价会非常大。本python代码包括向量化、向量数据库存储、调用OpenAI等等部分。用到的第三方库包括wechaty,pgvector,qrcode,HTMLParser,Pillow等等。
本文档的作用只是起到抛砖引玉的作用,供广大爱好者或者相关行业工作者学习或借鉴。
这些时间,随着ChatGPT的爆火,各种基于大语言模型的应用如何雨后春笋般出现,同时也再一次带火了Python语言以及NodeJS。通过这段时间的学习,发现基于Python语言开发的第三方库非常多,而且很多库非常成熟,都是经历过各种项目的考验。例如这个项目用到的核心组件wechaty,它是一个开源的Python库,用于构建微信机器人。它提供了与微信客户端进行交互的功能,可以实现自动化发送消息、接收消息、管理联系人、处理群聊等微信相关的操作。
wechaty的主要功能包括:
消息处理:可以接收和发送文本消息、图片、语音、视频等多种类型的消息,可以处理私聊消息和群聊消息。
联系人管理:可以获取联系人列表、查找联系人、添加联系人、删除联系人等操作,可以获取联系人的详细信息,如昵称、头像等。
群聊管理:可以获取群聊列表、查找群聊、创建群聊、加入群聊、退出群聊等操作,可以获取群聊的成员列表、发送群聊消息等。
事件处理:可以处理各种微信相关的事件,如登录事件、退出事件、消息接收事件、联系人变更事件等。
插件扩展:可以通过编写插件来扩展wechaty的功能,实现自定义的消息处理、事件处理等。
使用wechaty可以方便地构建各种微信机器人,如自动回复机器人、群聊管理机器人、消息提醒机器人等。它提供了简洁的API和丰富的功能,使得开发者可以快速搭建和定制自己的微信机器人。需要注意的是,wechaty是一个第三方库,它并非官方提供的API,因此在使用时需要遵守微信的使用规范和限制,以确保合法合规地使用微信相关功能。
另外,本项目还用到了Pillow,它是一个Python图像处理库,它是基于Python Imaging Library (PIL)的一个分支。Pillow提供了丰富的图像处理功能,可以打开、操作和保存多种图像格式的图像文件。
Pillow库可以用于各种图像处理任务,包括但不限于以下功能:
图像打开和保存:可以打开和保存多种图像格式的图像文件,如JPEG、PNG、BMP、GIF等。
图像缩放和裁剪:可以调整图像的大小,缩放图像或裁剪图像的一部分。
图像旋转和翻转:可以旋转图像的角度,或者水平/垂直翻转图像。
图像滤镜和效果:可以应用各种滤镜和效果,如模糊、锐化、边缘检测等。
图像调整和处理:可以调整图像的亮度、对比度、色彩平衡等属性,或者进行图像的颜色空间转换。
图像合成和叠加:可以将多个图像合成为一个图像,或者在图像上叠加文字、图形等元素。
图像信息和处理:可以获取图像的尺寸、颜色模式、像素值等信息,或者对图像进行像素级别的处理。
Pillow库易于使用,并且具有广泛的应用领域,包括图像处理、计算机视觉、图像识别、图像生成等。无论是简单的图像处理还是复杂的图像分析,Pillow都提供了丰富的功能和灵活的接口,方便开发者进行图像处理和操作。
为了实现预制问题的解答,企起期团队开发了对应的插件,当匹配度达到设置的标准时,则用预制问题进行解答,当匹配度没有达到标准时,则转由对应的大模型进行处理。
以下通过问答检索和插件实现来进行代码讲解。
传统的句子匹配一般使用like方式或者是用搜索引擎的分词方式。而在AI领域进行文本匹配,用的最多的方式是向量匹配。向量匹配方法的基本思想是将文本表示为一个向量,然后计算不同向量之间的距离或夹角,以此来衡量它们的相似程度。常见的向量匹配方法包括余弦相似度、欧几里得距离、Jaccard相似度等。不同的公司提供不同的向量化方式,市面上比较火的向量化方式包括:
Word2Vec:Word2Vec是一种基于神经网络的词向量表示方法,通过训练模型将每个词映射为一个固定长度的向量。准确性较高,能够捕捉到词语之间的语义关系。
GloVe:GloVe是一种基于全局词频统计的词向量表示方法,通过矩阵分解的方式将词语表示为向量。准确性较高,能够捕捉到词语之间的语义关系。
FastText:FastText是一种基于子词的词向量表示方法,通过将词语拆分为子词并将子词的向量表示进行平均或加权平均得到词向量。准确性较高,能够处理未登录词和词语的变形形式。
BERT:BERT是一种基于Transformer的预训练语言模型,通过训练模型将每个词语表示为一个上下文相关的向量。准确性较高,能够捕捉到词语的上下文信息。
由于各个公司的大语言模型的训练的数据规模和质量以及模型架构不同,导致向量化匹配的准确度存在差距,当然随着时间的推移,未来肯定会出现越来越准确的匹配算法。目前看,相对比较准确的有OpenAI,文心一言,BERT等等。
本项目采用的是OpenAI提供的接口进行向量化,向量化的数据存储在pgvector向量数据库中,问题的相似度匹配调用了postgresql写的函数。
代码如下:
import psycopg2
import configparser
import openai
import os
from common.log import logger
curdir = os.path.dirname(__file__)
# 读取配置文件
config = configparser.ConfigParser()
config_path = os.path.join(curdir, "config.ini")
config.read(config_path)
# 从配置文件中获取数据库连接信息
host = config.get('database', 'host')
port = config.get('database', 'port')
database = config.get('database', 'database')
user = config.get('database', 'user')
password = config.get('database', 'password')
api_key = config.get('database', 'api_key')
# 从配置文件中获取期望的相似度,低于该相似度的问题则舍弃掉
expect_similarity = config.get('similarity', 'expect_similarity')
def getAnswer(question):
# 连接数据库
conn = psycopg2.connect(
host=host,
port=port,
database=database,
user=user,
password=password
)
# 创建游标
cur = conn.cursor()
# 调用OpenAI的嵌入API获取嵌入值
openai.api_key = api_key
response = openai.Embedding.create(
model="text-embedding-ada-002",
input=question
)
# 提取嵌入值
embedding = response["data"][0]["embedding"]
#print(embedding)
# 执行查询语句
#cur.execute("SELECT question,answer,tokens FROM tb_qa")
# 执行函数
cur.execute("SELECT * FROM match_questions(%s::vector,0.5,3,1)",(embedding,))
# 获取查询结果
results = cur.fetchall()
answer = ''
if len(results)>0:
similarity = results[0][4]
logger.info(f"从数据库中进行向量匹配 问题={question} 匹配到的数据库中的问题={results[0][1]} 匹配到的数据库中的答案={results[0][2]} 匹配的相似度={results[0][4]} 要求的相似度={expect_similarity}")
if similarity>=float(expect_similarity):
answer = results[0][2]
# 关闭游标和连接
cur.close()
conn.close()
return answer以上代码首先导入了所需的模块和库,包括psycopg2、configparser、openai、os、common.log等,然后,创建了一个getAnswer的函数。
代码的开始首先是通过读取config.ini配置文件,得到对应的数据库连接相关信息,以及期望的匹配度信息。然后通过psycopg2连接数据库并从连接中创建游标。
其次根据传递过来的问题,调用openai的相关embedding接口,得到对应问题的向量值。再然后通过游标执行对应的函数得到返回结果。
当返回的结果不为空时,则是判断相似度,如果相似度达到配置文件中的设置,则返回对应的答案,否则返回空进行下一步处理。
以下是postgresql的match_questions函数:
CREATE OR REPLACE FUNCTION "public"."match_questions"("embedding" "public"."vector", "match_threshold" float8, "match_count" int4, "min_content_length" int4)
RETURNS TABLE("id" int8, "question" text, "answer" text, "token" int4, "similarity" float8) AS $BODY$
#variable_conflict use_variable
begin
return query
select
tb_qa.id,
tb_qa.question,
tb_qa.answer,
tb_qa.tokens,
(tb_qa.embedding <#> embedding) * -1 as similarity
from tb_qa
where length(tb_qa.question) >= min_content_length
and (tb_qa.embedding <#> embedding) * -1 > match_threshold
order by tb_qa.embedding <#> embedding
limit match_count;
end;
$BODY$
LANGUAGE plpgsql VOLATILE
COST 100
ROWS 1000从以上数据库的函数可以看出,根据传过来的embedding变量,通过计算返回对应的数据库记录。函数的参数有4个:
embedding: 问题的向量数据
match_threshold:期望的匹配度
match_count:返回的结果集数量限制
min_content_length:最小的内容限制
其中<#>就是表示2个向量的相似度运算符
当微信中发送相关消息时,需要截留住消息进行预制问题的匹配,如果没有匹配到结果,则按照原来的逻辑继续由大语言模型进行回答。以下是qiqiqi插件相关代码:
# encoding:utf-8
import plugins
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from channel.chat_message import ChatMessage
from common.log import logger
from plugins import *
from .pgvector import getAnswer
@plugins.register(
name="QIQIQI",
desire_priority=800,
hidden=True,
desc="企起期微信助手",
version="0.1",
author="qiqiqi",
)
class QIQIQI(Plugin):
def __init__(self):
super().__init__()
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
logger.info("[QIQIQI] inited")
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type not in [
ContextType.TEXT,
ContextType.JOIN_GROUP,
ContextType.PATPAT,
]:
return
if e_context["context"].type == ContextType.JOIN_GROUP:
e_context["context"].type = ContextType.TEXT
msg: ChatMessage = e_context["context"]["msg"]
e_context["context"].content = f'请你用软件公司客服的风格说一句问候语来欢迎新用户"{msg.actual_user_nickname}"加入群聊。'
e_context.action = EventAction.BREAK # 事件结束,进入默认处理逻辑
return
if e_context["context"].type == ContextType.PATPAT:
e_context["context"].type = ContextType.TEXT
msg: ChatMessage = e_context["context"]["msg"]
e_context["context"].content = f"请你用软件公司客服的风格介绍你自己。"
e_context.action = EventAction.BREAK # 事件结束,进入默认处理逻辑
return
content = e_context["context"].content
logger.debug("[QIQIQI] on_handle_context. content: %s" % content)
answer = getAnswer(content)
if answer!='':
reply = Reply()
reply.type = ReplyType.TEXT
msg: ChatMessage = e_context["context"]["msg"]
reply.content = answer
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑
else:
e_context.action = EventAction.CONTINUE
def get_help_text(self, **kwargs):
help_text = "输入问题,我会回复问题对应的答案,问题和答案都在qiqiqi智能助手系统进行维护"
return help_text从以上代码可以看出,首先判断消息是否是文本消息以及入群消息或者是微信拍拍消息,如果不是上述3种消息的一种,则直接返回不进行任何处理。
如果传递过来的消息是加入群聊的消息或者是微信拍拍的消息,则按照预制的提示语,用对应的大语言模型进行回复。
当过来的微信消息是文本消息时,则调用上述提到的getAnswer方法进行预制问题的回答,如果数据库中匹配到了对应的答案,则直接返回答案并停止后续的相关处理,如果没有匹配到对应的答案,则按照程序的主逻辑继续进行。
以下是微信端运行的效果,用"/"符号进行问题提问,该符号可以在配置文件中进行配置。
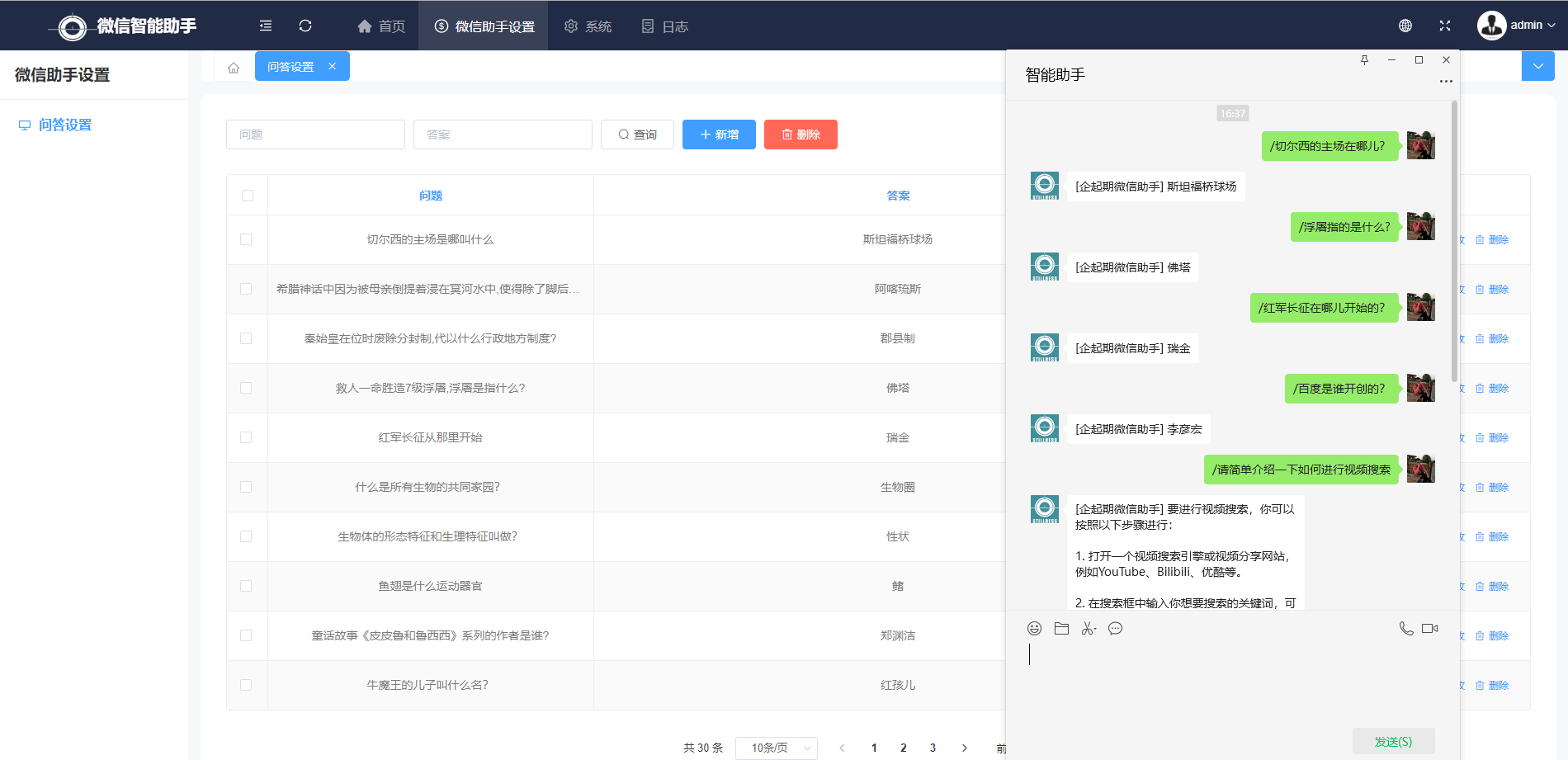
从上图中可以看出,提出的问题并不是完全匹配数据库中录入的问题,但匹配的结果的准确度达到了100%,这就是向量匹配的能力!
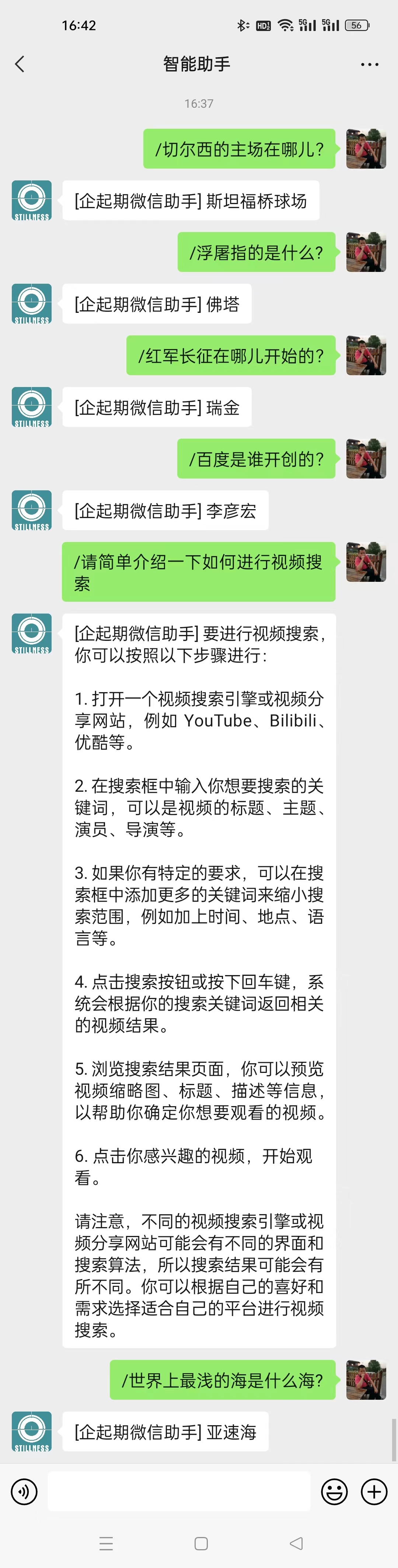
从上面的微信长截屏可以看出,当提的问题在数据库中找不到预制答案时,系统会自动调用大语言模型进行问题解答。实际上,在现实的业务中,这儿可以改用调公司的其他接口进行问题解答,或者发送相关消息,引入人工进行客服工作。
本项目只是抛砖引玉的作用,现实中,可以根据实际场景做机器人客服,或者公司数据实时查询,或者其他什么相关的服务。用微信或者微信公众号或者微信企业号,甚至可以直接对接WhatsApp,Discord等等,当然也支持网页版本或者手机app。输入和输出也不仅仅是文本消息,也可以支持语音输入,语音输出,图片输出等等。当然,需要进行对应的开发工作!
欢迎感兴趣的企业或朋友进行沟通,让人工智能真正能服务人类,创造价值!!!
扫码关注不迷路!!!
郑州升龙商业广场B座25层
service@iqiqiqi.cn

联系电话:187-0363-0315
联系电话:199-3777-5101





