
LangChain通过可组合性使用大型语言模型构建应用程序。 各种LLM(大语言模型)的用法不一致,且每个大语言模型有很多种使用技巧。如果要想把各种LLM集成到一起使用,LangChain的优势就发挥出来了,它提供了各种标准化的接口,而且使得操作LLM变的简单。
根据使用方式的不同,模型可分为纯文本模型,聊天模型,嵌入式模型等等。在AI的领域,还包括处理语音的模型,处理图片的模型等等。 如果一个模型既能处理文本又能处理视频,则称之为多模态模型。
目前通过看LangChain的文档,并没有发现它支持语音、图片、视频等等的模型。目前看主要还是为了方便处理大语言模型。
LangChain支持非常多的大语言模型,常用的如OpenAI,Cohere,Hugging Face Hub等等。列表如下图:


未来如果有新的大语言模型出现,相信LangChain也会集成进去。只是目前不确定能被它集成的标准是什么,一定的知名度还是足够开放?
当然我们也可以通过LangChain提供的方法集成自己的模型,按照文档的描述,好像并不是很复杂,因为对应的标准接口本身参数也不是很多。
聊天模型实际上是文本模型的一种特殊应用,但确实还是有一些不一样的地方。LangChain规范了四种聊天模版,常用的实际上有三种就够用。
from langchain.chat_models import ChatOpenAI from langchain import PromptTemplate, LLMChain from langchain.prompts.chat import ( ChatPromptTemplate, SystemMessagePromptTemplate, AIMessagePromptTemplate, HumanMessagePromptTemplate, ) from langchain.schema import ( AIMessage, HumanMessage, SystemMessage )
您可以通过将一条或多条消息传递给聊天模型来获得聊天完成。响应将是一条消息。LangChain 目前支持的消息类型有AIMessage, HumanMessage, SystemMessage, 和ChatMessage–ChatMessage接受任意角色参数。大多数时候,你只会处理HumanMessage, AIMessage, 和SystemMessage。
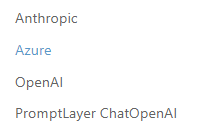
同理,LangChain也支持非常多的聊天模型,如下:
Embedding 类是设计用于与嵌入交互的类。有很多嵌入提供程序(OpenAI、Cohere、Hugging Face 等)——此类旨在为所有这些提供标准接口。
嵌入创建一段文本的矢量表示。这很有用,因为这意味着我们可以考虑向量空间中的文本,并执行语义搜索之类的操作,我们可以在向量空间中寻找最相似的文本片段。
LangChain 中的基础 Embedding 类公开了两个方法:embed_documents和embed_query。最大的区别在于这两种方法具有不同的接口:一种处理多个文档,而另一种处理单个文档。除此之外,将它们作为两种独立方法的另一个原因是一些嵌入提供者对文档(要搜索的)和查询(搜索查询本身)有不同的嵌入方法。
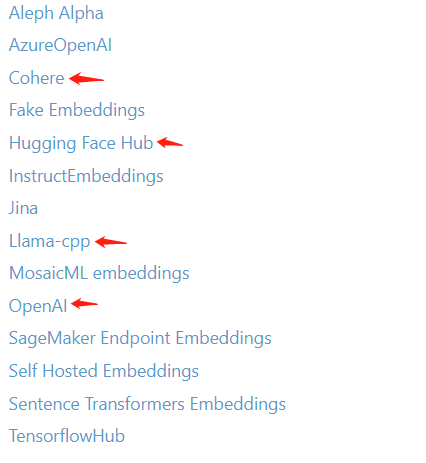
同理,LangChain也集成了很多嵌入模型,如下:
PromptTemplates 负责构建提示值。这些提示模板可以执行格式化、示例选择等操作。在高层次上,这些基本上是公开format_prompt构造提示的方法的对象。在引擎盖下,任何事情都可能发生。
from langchain.prompts import PromptTemplate, ChatPromptTemplate
string_prompt = PromptTemplate.from_template("tell me a joke about {subject}")
chat_prompt = ChatPromptTemplate.from_template("tell me a joke about {subject}")
string_prompt_value = string_prompt.format_prompt(subject="soccer")
chat_prompt_value = chat_prompt.format_prompt(subject="soccer")
string_prompt_value.to_string()
'tell me a joke about soccer'
chat_prompt_value.to_string()
'Human: tell me a joke about soccer'
string_prompt_value.to_messages()
[HumanMessage(content='tell me a joke about soccer', additional_kwargs={}, example=False)]
chat_prompt_value.to_messages()
[HumanMessage(content='tell me a joke about soccer', additional_kwargs={}, example=False)]聊天模型将聊天消息列表作为输入——这个列表通常称为提示。这些聊天消息不同于原始字符串(您将传递给LLM模型),因为每条消息都与一个角色相关联。
例如,在 OpenAI Chat Completion API中,聊天消息可以与 AI、人类或系统角色相关联。该模型应该更紧密地遵循系统聊天消息的指令。
为此,LangChain提供了几个相关的提示模板,方便构建和使用提示。我们鼓励您在查询聊天模型时使用这些与聊天相关的提示模板PromptTemplate,以充分利用底层聊天模型的潜力。
from langchain.prompts import (
ChatPromptTemplate,
PromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
template="You are a helpful assistant that translates {input_language} to {output_language}."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
prompt=PromptTemplate(
template="You are a helpful assistant that translates {input_language} to {output_language}.",
input_variables=["input_language", "output_language"],
)
system_message_prompt_2 = SystemMessagePromptTemplate(prompt=prompt)
assert system_message_prompt == system_message_prompt_2
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
# get a chat completion from the formatted messages
chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages()
[SystemMessage(content='You are a helpful assistant that translates English to French.', additional_kwargs={}),
HumanMessage(content='I love programming.', additional_kwargs={})]If you have a large number of examples, you may need to select which ones to include in the prompt. The ExampleSelector is the class responsible for doing so.
The base interface is defined as below:
class BaseExampleSelector(ABC): """Interface for selecting examples to include in prompts.""" @abstractmethod def select_examples(self, input_variables: Dict[str, str]) -> List[dict]: """Select which examples to use based on the inputs."""
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
# These are a lot of examples of a pretend task of creating antonyms.
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_selector = SemanticSimilarityExampleSelector.from_examples(
# This is the list of examples available to select from.
examples,
# This is the embedding class used to produce embeddings which are used to measure semantic similarity.
OpenAIEmbeddings(),
# This is the VectorStore class that is used to store the embeddings and do a similarity search over.
Chroma,
# This is the number of examples to produce.
k=1
)
similar_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
# Input is a feeling, so should select the happy/sad example
print(similar_prompt.format(adjective="worried"))
'''
Give the antonym of every input
Input: happy
Output: sad
Input: worried
Output:
# Input is a measurement, so should select the tall/short example
print(similar_prompt.format(adjective="fat"))
Give the antonym of every input
Input: happy
Output: sad
Input: fat
Output:
# You can add new examples to the SemanticSimilarityExampleSelector as well
similar_prompt.example_selector.add_example({"input": "enthusiastic", "output": "apathetic"})
print(similar_prompt.format(adjective="joyful"))
Give the antonym of every input
Input: happy
Output: sad
Input: joyful
Output:
'''说直白点就是LangChain包装了你的Prompt,通过output parser可以把包装后的prompt输出出来。当然, LangChain有好多种包装模式,以下举一个OutputfixingParser的例子:
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
from langchain.llms import OpenAI
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
class Actor(BaseModel):
name: str = Field(description="name of an actor")
film_names: List[str] = Field(description="list of names of films they starred in")
actor_query = "Generate the filmography for a random actor."
parser = PydanticOutputParser(pydantic_object=Actor)
misformatted = "{'name': 'Tom Hanks', 'film_names': ['Forrest Gump']}"
parser.parse(misformatted)
'''
---------------------------------------------------------------------------
JSONDecodeError Traceback (most recent call last)
File ~/workplace/langchain/langchain/output_parsers/pydantic.py:23, in PydanticOutputParser.parse(self, text)
22 json_str = match.group()
---> 23 json_object = json.loads(json_str)
24 return self.pydantic_object.parse_obj(json_object)
File ~/.pyenv/versions/3.9.1/lib/python3.9/json/__init__.py:346, in loads(s, cls, object_hook, parse_float, parse_int, parse_constant, object_pairs_hook, **kw)
343 if (cls is None and object_hook is None and
344 parse_int is None and parse_float is None and
345 parse_constant is None and object_pairs_hook is None and not kw):
--> 346 return _default_decoder.decode(s)
347 if cls is None:
File ~/.pyenv/versions/3.9.1/lib/python3.9/json/decoder.py:337, in JSONDecoder.decode(self, s, _w)
333 """Return the Python representation of ``s`` (a ``str`` instance
334 containing a JSON document).
335
336 """
--> 337 obj, end = self.raw_decode(s, idx=_w(s, 0).end())
338 end = _w(s, end).end()
File ~/.pyenv/versions/3.9.1/lib/python3.9/json/decoder.py:353, in JSONDecoder.raw_decode(self, s, idx)
352 try:
--> 353 obj, end = self.scan_once(s, idx)
354 except StopIteration as err:
JSONDecodeError: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
During handling of the above exception, another exception occurred:
OutputParserException Traceback (most recent call last)
Cell In[6], line 1
----> 1 parser.parse(misformatted)
File ~/workplace/langchain/langchain/output_parsers/pydantic.py:29, in PydanticOutputParser.parse(self, text)
27 name = self.pydantic_object.__name__
28 msg = f"Failed to parse {name} from completion {text}. Got: {e}"
---> 29 raise OutputParserException(msg)
OutputParserException: Failed to parse Actor from completion {'name': 'Tom Hanks', 'film_names': ['Forrest Gump']}. Got: Expecting property name enclosed in double quotes: line 1 column 2 (char 1)
Now we can construct and use a OutputFixingParser. This output parser takes as an argument another output parser but also an LLM with which to try to correct any formatting mistakes.
'''
from langchain.output_parsers import OutputFixingParser
new_parser = OutputFixingParser.from_llm(parser=parser, llm=ChatOpenAI())
new_parser.parse(misformatted)
Actor(name='Tom Hanks', film_names=['Forrest Gump'])默认情况下,Chains 和 Agents 是无状态的,这意味着它们独立地处理每个传入的查询(底层 LLM 和聊天模型也是如此)。在某些应用程序中(聊天机器人就是一个很好的例子),记住以前的交互非常重要,无论是短期的还是长期的。“内存”的概念正是为了做到这一点而存在的。
LangChain 提供两种形式的记忆组件。首先,LangChain 提供了用于管理和操作以前的聊天消息的辅助实用程序。这些被设计为模块化且有用,无论它们如何使用。其次,LangChain 提供了将这些实用程序合并到链中的简单方法。
提供了以下文档部分:
说直白点,就是有些场景是需要记住刚刚说过的话的,例如聊天场景,如果没有LangChain的情况下,需要自己去封装Prompt,且及其容易超过Token数量,用LangChian,解决了这些问题。而且通过总结内容等相关技术,可以节省很多token,并保存更多轮对话。
LangChain不单单只是简单的把会话内容存入到内存中,他还支持很多种方式,例如:
The first set of examples all highlight different types of memory.
The examples here all highlight how to use memory in different ways.
索引指的是构建文档的方式,以便 LLM 可以最好地与它们交互。该模块包含用于处理文档、不同类型索引的实用函数,以及在链中使用这些索引的示例。
在链中使用索引的最常见方式是在“检索”步骤中。此步骤指的是接受用户的查询并返回最相关的文档。我们之所以做出这种区分,是因为 (1) 索引可以用于检索以外的其他用途,以及 (2) 检索可以使用索引以外的其他逻辑来查找相关文档。因此,我们有一个“检索器”接口的概念——这是大多数链使用的接口。
大多数时候,当我们谈论索引和检索时,我们谈论的是索引和检索非结构化数据(如文本文档)。要与结构化数据(SQL 表等)或 API 进行交互,请参阅相应的用例部分以获取相关功能的链接。LangChain 支持的主要索引和检索类型目前以矢量数据库为中心,因此我们深入研究了这些主题的许多功能。
有关与此相关的所有内容的概述,请参阅下面的入门笔记本:
We then provide a deep dive on the four main components.
Document Loaders
How to load documents from a variety of sources.
Text Splitters
An overview of the abstractions and implementions around splitting text.
VectorStores
An overview of VectorStores and the many integrations LangChain provides.
Retrievers
An overview of Retrievers and the implementations LangChain provides.
说直白点,就是当需要通过LLM处理一个文档或者很多文档时,传统的数据库技术和搜索引擎技术是通过like或者分词及索引实现快速搜索。用AI后,实际上使用的是向量匹配,但是向量匹配需要占用大量的资源,因此需要把文档加载进来(doc,ppt,pdf,text,md,html等等),然后切分这个文档,然后存储切分的文档到向量数据库,在然后就是检索相似度了。 LangChain把这一系列都进行了封装,让你的操作非常简单。
首先LangChain能处理的文档类型就有很多,例如:
These transform loaders transform data from a specific format into the Document format. For example, there are transformers for CSV and SQL. Mostly, these loaders input data from files but sometime from URLs.
A primary driver of a lot of these transformers is the Unstructured python package. This package transforms many types of files - text, powerpoint, images, html, pdf, etc - into text data.
For detailed instructions on how to get set up with Unstructured, see installation guidelines here.
These datasets and sources are created for public domain and we use queries to search there and download necessary documents. For example, Hacker News service.
We don’t need any access permissions to these datasets and services.
These datasets and services are not from the public domain. These loaders mostly transform data from specific formats of applications or cloud services, for example Google Drive.
We need access tokens and sometime other parameters to get access to these datasets and services.
如上显示,LangChain感觉几乎能处理所有的格式,甚至哔哩哔哩视频,其实LangChain是制定了一些标准的接口,本质上解释各种文档还是利用第三方的组件。用哔哩哔哩举例,如下:
#!pip install bilibili-api-python from langchain.document_loaders import BiliBiliLoader loader = BiliBiliLoader( ["https://www.bilibili.com/video/BV1xt411o7Xu/"] ) loader.load()
由于文档的格式各种各样,且不同的文档或文章断句的方式完全不同,因此LangChain支持很多种文档切分的方式。
默认推荐的文本拆分器是 RecursiveCharacterTextSplitter。此文本拆分器采用字符列表。它尝试根据第一个字符的拆分来创建块,但如果任何块太大,它就会移动到下一个字符,依此类推。默认情况下,它尝试拆分的字符是["\n\n", "\n", " ", ""]
除了控制可以拆分的字符外,您还可以控制其他一些内容:
length_function: 如何计算块的长度。默认只计算字符数,但在这里传递令牌计数器是很常见的。
chunk_size:块的最大大小(由长度函数测量)。
chunk_overlap:块之间的最大重叠。有一些重叠可以很好地保持块之间的一些连续性(例如,做一个滑动窗口)。
通过查看LangChain的文档,目前提供的方便的切分方式有以下几种:

根据上图可以看出,针对不同的文档,LangChain优化了切分的方式。例如针对字符切分的方式就是"\n\n";针对Markdown格式文档,切分的方式就是MarkDown特殊的分隔符了;针对自然语言文章,NLTK方式的切分可能是一些语义理解的单词,总之,LangChain非常灵活,甚至还有专门切分Python代码的方式。以下的提示是指自然语言方式切分文章:
The Natural Language Toolkit, or more commonly NLTK, is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in the Python programming language.
Rather than just splitting on “\n\n”, we can use NLTK to split based on NLTK tokenizers.
How the text is split: by NLTK tokenizer.
How the chunk size is measured:by number of characters
向量存储是指把得到的向量数据存储到对应的库或者文件格式中,不同的方式得到的向量匹配的结果会差异比较大,目前看,OpenAI的向量匹配效果比较好。向量的匹配按照数学的方式,也有很多算法,例如.余弦相似度(Cosine similarity)、皮尔逊相关系数(Pearson Correlation Coefficient)、欧几里得距离(Euclidean Distance)、杰卡德距离(Jaccard Distance)
常用的10种向量数据库: 10个顶级矢量数据库
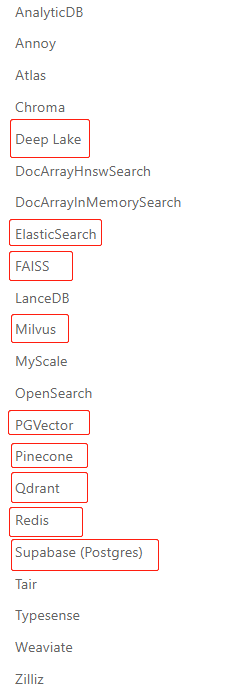
LangChain支持市面上大多数的向量库,如下图:
检索器接口是一个通用接口,可以轻松地将文档与语言模型结合起来。此接口公开了一个get_relevant_documents方法,该方法接受一个查询(一个字符串)并返回一个文档列表。
LangChain支持的检索器列表如下:
单独使用 LLM 对于一些简单的应用程序来说很好,但许多更复杂的应用程序需要链接 LLMs - 彼此或与其他专家链接。LangChain 提供了 Chains 的标准接口,以及一些常见的 Chain 实现,方便使用。
链允许我们将多个组件组合在一起以创建一个单一的、连贯的应用程序。例如,我们可以创建一个接受用户输入的链,使用 PromptTemplate 对其进行格式化,然后将格式化后的响应传递给 LLM。我们可以通过将多个链组合在一起,或者通过将链与其他组件组合来构建更复杂的链。
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate(
input_variables=["product"],
template="What is a good name for a company that makes {product}?",
)
# 我们现在可以创建一个非常简单的链,它将接受用户输入,用它格式化提示,然后将它发送给 LLM。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Run the chain only specifying the input variable.
print(chain.run("colorful socks"))
#如果有多个变量,您可以使用字典一次输入它们。
prompt = PromptTemplate(
input_variables=["company", "product"],
template="What is a good name for {company} that makes {product}?",
)
chain = LLMChain(llm=llm, prompt=prompt)
print(chain.run({
'company': "ABC Startup",
'product': "colorful socks"
}))Chain支持将BaseMemory对象作为memory参数,允许Chain对象在多次调用中持久保存数据。换句话说,它创建了Chain一个有状态的对象。
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
conversation = ConversationChain(
llm=chat,
memory=ConversationBufferMemory()
)
conversation.run("Answer briefly. What are the first 3 colors of a rainbow?")
# -> The first three colors of a rainbow are red, orange, and yellow.
conversation.run("And the next 4?")
# -> The next four colors of a rainbow are green, blue, indigo, and violet.Chain设置verbose为将在运行时True打印出对象的一些内部状态。
调用语言模型后的下一步是对语言模型进行一系列调用。我们可以使用顺序链来做到这一点,顺序链是按预定义顺序执行其链接的链。具体来说,我们将使用SimpleSequentialChain. 这是最简单的顺序链类型,其中每个步骤都有一个输入/输出,一个步骤的输出是下一个步骤的输入。
在本教程中,我们的顺序链将:
首先,为产品创建公司名称。我们将重用LLMChain我们之前初始化的来创建这个公司名称。
然后,为产品创建一个标语。我们将初始化一个新的LLMChain来创建这个标语,如下所示。
second_prompt = PromptTemplate(
input_variables=["company_name"],
template="Write a catchphrase for the following company: {company_name}",
)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
#现在我们可以将这两个 LLMChain 结合起来,这样我们就可以一步创建一个公司名称和一个标语。
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# Run the chain specifying only the input variable for the first chain.
catchphrase = overall_chain.run("colorful socks")
print(catchphrase)from langchain.chains import LLMChain
from langchain.chains.base import Chain
from typing import Dict, List
class ConcatenateChain(Chain):
chain_1: LLMChain
chain_2: LLMChain
@property
def input_keys(self) -> List[str]:
# Union of the input keys of the two chains.
all_input_vars = set(self.chain_1.input_keys).union(set(self.chain_2.input_keys))
return list(all_input_vars)
@property
def output_keys(self) -> List[str]:
return ['concat_output']
def _call(self, inputs: Dict[str, str]) -> Dict[str, str]:
output_1 = self.chain_1.run(inputs)
output_2 = self.chain_2.run(inputs)
return {'concat_output': output_1 + output_2}A chain is made up of links, which can be either primitives or other chains. Primitives can be either prompts, models, arbitrary functions, or other chains. The examples here are broken up into three sections:
Covers both generic chains (that are useful in a wide variety of applications) as well as generic functionality related to those chains.
Chains related to working with indexes.
All other types of chains!
Router Chains: Selecting from multiple prompts with MultiPromptChain
Router Chains: Selecting from multiple prompts with MultiRetrievalQAChain
某些应用程序不仅需要预先确定的对 LLM/其他工具的调用链,还可能需要依赖于用户输入的未知链。在这些类型的链中,有一个“代理”可以访问一套工具。根据用户输入,代理可以决定调用这些工具中的哪一个(如果有的话)。
目前,主要有两种类型的代理:
“行动代理人”:这些代理人决定采取行动并一次采取该行动
“计划和执行代理”:这些代理首先决定要采取的行动计划,然后一次执行这些行动。
你应该什么时候使用每一个?动作代理更传统,适合小任务。对于更复杂或长期运行的任务,初始规划步骤有助于保持长期目标和重点。然而,这是以通常更多的调用和更高的延迟为代价的。这两个代理也不是相互排斥的——事实上,通常最好让一个行动代理负责计划和执行代理的执行。
代理的高级伪代码类似于:
收到一些用户输入
代理决定使用哪个工具(如果有的话),以及该工具的输入应该是什么
然后使用该工具输入调用该工具,并记录观察结果(这只是使用该工具输入调用该工具的输出)
工具、工具输入和观察的历史被传回代理,它决定下一步采取什么步骤。
重复此操作,直到代理决定不再需要使用工具,然后直接响应用户。
Agent中涉及的不同抽象如下:
代理:这是应用程序逻辑所在的地方。代理公开一个接口,该接口接收用户输入以及代理之前执行的一系列步骤,并返回AgentAction或AgentFinish
AgentAction对应于要使用的工具和该工具的输入
AgentFinish意味着代理已经完成,并且有关于返回给用户什么的信息
工具:这些是代理可以采取的行动。您为座席提供的工具在很大程度上取决于您希望座席做什么
工具包:这些是为特定用例设计的工具组。例如,为了让代理以最佳方式与 SQL 数据库交互,它可能需要访问一个工具来执行查询和另一个工具来检查表。
代理执行器:它包装了一个代理和一系列工具。这负责迭代运行代理直到满足停止条件的循环。
上面四个要理解的最重要的抽象是代理的抽象。尽管可以以任何选择的方式定义代理,但构建代理的典型方法是:
PromptTemplate:负责获取用户输入和之前的步骤,并构建提示以发送到语言模型
语言模型:这采用由 PromptTemplate 构造的提示并返回一些输出
输出解析器:获取语言模型的输出并将其解析为AgentAction或AgentFinish对象。
在这部分文档中,我们首先从入门笔记本开始,介绍如何以端到端的方式使用与代理相关的所有内容。
然后我们将文档分成以下部分:
工具
在本节中,我们将介绍 LangChain 原生支持的不同类型的工具。然后我们介绍如何添加您自己的工具。
代理商
在本节中,我们将介绍 LangChain 原生支持的不同类型的代理。然后我们介绍如何修改和创建您自己的代理。
工具包
在本节中,我们将介绍 LangChain 开箱即用支持的各种工具包,以及如何从中创建代理。
代理执行器
在本节中,我们将介绍 Agent Executor 类,它负责循环调用代理和工具。我们介绍了自定义此功能的不同方法,以及您可以使用的选项以进行更多控制。
更深入
代理的高级伪代码类似于:
收到一些用户输入
计划者列出了要采取的步骤
执行者遍历步骤列表,执行它们
最典型的实现方式是规划器是语言模型,执行器是动作代理。
更深入
工具是代理可以用来与世界交互的功能。这些工具可以是通用实用程序(例如搜索)、其他链,甚至是其他代理.
#目前,可以使用以下代码片段加载工具: from langchain.agents import load_tools tool_names = [...] tools = load_tools(tool_names) #一些工具(例如链、代理)可能需要一个基础 LLM 来初始化它们。在这种情况下,您也可以传入 LLM: from langchain.agents import load_tools tool_names = [...] llm = ... tools = load_tools(tool_names, llm=llm)
以下是所有支持的工具和相关信息的列表:
工具名称:LLM 引用工具的名称。
工具描述:传递给 LLM 的工具的描述。
注意事项:有关未传递给 LLM 的工具的注意事项。
需要 LLM:此工具是否需要初始化 LLM。
(可选)额外参数:初始化此工具需要哪些额外参数。
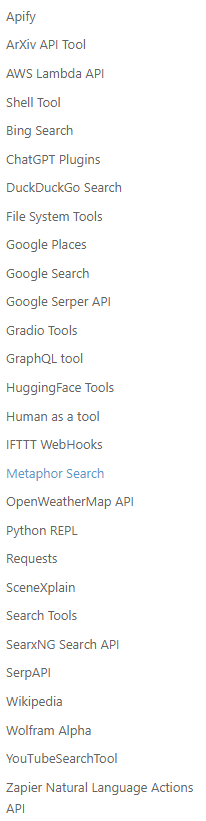
LangChain支持很多种工具,并且支持自定义工具,以下是支持的工具的清单:
python_repl
Tool Name: Python REPL
Tool Description: A Python shell. Use this to execute python commands. Input should be a valid python command. If you expect output it should be printed out.
Notes: Maintains state.
Requires LLM: No
serpapi
Tool Name: Search
Tool Description: A search engine. Useful for when you need to answer questions about current events. Input should be a search query.
Notes: Calls the Serp API and then parses results.
Requires LLM: No
wolfram-alpha
Tool Name: Wolfram Alpha
Tool Description: A wolfram alpha search engine. Useful for when you need to answer questions about Math, Science, Technology, Culture, Society and Everyday Life. Input should be a search query.
Notes: Calls the Wolfram Alpha API and then parses results.
Requires LLM: No
Extra Parameters: wolfram_alpha_appid: The Wolfram Alpha app id.
requests
Tool Name: Requests
Tool Description: A portal to the internet. Use this when you need to get specific content from a site. Input should be a specific url, and the output will be all the text on that page.
Notes: Uses the Python requests module.
Requires LLM: No
terminal
Tool Name: Terminal
Tool Description: Executes commands in a terminal. Input should be valid commands, and the output will be any output from running that command.
Notes: Executes commands with subprocess.
Requires LLM: No
pal-math
Tool Name: PAL-MATH
Tool Description: A language model that is excellent at solving complex word math problems. Input should be a fully worded hard word math problem.
Notes: Based on this paper.
Requires LLM: Yes
pal-colored-objects
Tool Name: PAL-COLOR-OBJ
Tool Description: A language model that is wonderful at reasoning about position and the color attributes of objects. Input should be a fully worded hard reasoning problem. Make sure to include all information about the objects AND the final question you want to answer.
Notes: Based on this paper.
Requires LLM: Yes
llm-math
Tool Name: Calculator
Tool Description: Useful for when you need to answer questions about math.
Notes: An instance of the LLMMath chain.
Requires LLM: Yes
open-meteo-api
Tool Name: Open Meteo API
Tool Description: Useful for when you want to get weather information from the OpenMeteo API. The input should be a question in natural language that this API can answer.
Notes: A natural language connection to the Open Meteo API (https://api.open-meteo.com/), specifically the /v1/forecast endpoint.
Requires LLM: Yes
news-api
Tool Name: News API
Tool Description: Use this when you want to get information about the top headlines of current news stories. The input should be a question in natural language that this API can answer.
Notes: A natural language connection to the News API (https://newsapi.org), specifically the /v2/top-headlines endpoint.
Requires LLM: Yes
Extra Parameters: news_api_key (your API key to access this endpoint)
tmdb-api
Tool Name: TMDB API
Tool Description: Useful for when you want to get information from The Movie Database. The input should be a question in natural language that this API can answer.
Notes: A natural language connection to the TMDB API (https://api.themoviedb.org/3), specifically the /search/movie endpoint.
Requires LLM: Yes
Extra Parameters: tmdb_bearer_token (your Bearer Token to access this endpoint - note that this is different from the API key)
google-search
Tool Name: Search
Tool Description: A wrapper around Google Search. Useful for when you need to answer questions about current events. Input should be a search query.
Notes: Uses the Google Custom Search API
Requires LLM: No
Extra Parameters: google_api_key, google_cse_id
For more information on this, see this page
searx-search
Tool Name: Search
Tool Description: A wrapper around SearxNG meta search engine. Input should be a search query.
Notes: SearxNG is easy to deploy self-hosted. It is a good privacy friendly alternative to Google Search. Uses the SearxNG API.
Requires LLM: No
Extra Parameters: searx_host
google-serper
Tool Name: Search
Tool Description: A low-cost Google Search API. Useful for when you need to answer questions about current events. Input should be a search query.
Notes: Calls the serper.dev Google Search API and then parses results.
Requires LLM: No
Extra Parameters: serper_api_key
For more information on this, see this page
wikipedia
Tool Name: Wikipedia
Tool Description: A wrapper around Wikipedia. Useful for when you need to answer general questions about people, places, companies, historical events, or other subjects. Input should be a search query.
Notes: Uses the wikipedia Python package to call the MediaWiki API and then parses results.
Requires LLM: No
Extra Parameters: top_k_results
podcast-api
Tool Name: Podcast API
Tool Description: Use the Listen Notes Podcast API to search all podcasts or episodes. The input should be a question in natural language that this API can answer.
Notes: A natural language connection to the Listen Notes Podcast API (https://www.PodcastAPI.com), specifically the /search/ endpoint.
Requires LLM: Yes
Extra Parameters: listen_api_key (your api key to access this endpoint)
openweathermap-api
Tool Name: OpenWeatherMap
Tool Description: A wrapper around OpenWeatherMap API. Useful for fetching current weather information for a specified location. Input should be a location string (e.g. London,GB).
Notes: A connection to the OpenWeatherMap API (https://api.openweathermap.org), specifically the /data/2.5/weather endpoint.
Requires LLM: No
Extra Parameters: openweathermap_api_key (your API key to access this endpoint)
在构建您自己的代理工具时,您需要为其提供一个它可以使用的工具列表。除了调用的实际函数外,该工具还包含几个组件:
名称(str),是必需的,并且在提供给代理的一组工具中必须是唯一的
description (str),可选但推荐,因为代理使用它来确定工具的使用
return_direct (bool), 默认为 False
args_schema (Pydantic BaseModel) 是可选的,但推荐使用,可用于提供更多信息(例如,少量示例)或对预期参数的验证。
为了更容易定义自定义工具,@tool提供了一个装饰器。这个装饰器可以用来Tool从一个简单的函数快速创建一个。默认情况下,装饰器使用函数名称作为工具名称,但这可以通过传递字符串作为第一个参数来覆盖。此外,装饰器将使用函数的文档字符串作为工具的描述。
from langchain.tools import tool
@tool
def search_api(query: str) -> str:
"""Searches the API for the query."""
return f"Results for query {query}"
#您还可以提供参数,例如工具名称以及是否直接返回。
@tool("search", return_direct=True)
def search_api(query: str) -> str:
"""Searches the API for the query."""
return "Results"
#您还可以提供args_schema有关参数的更多信息
class SearchInput(BaseModel):
query: str = Field(description="should be a search query")
@tool("search", return_direct=True, args_schema=SearchInput)
def search_api(query: str) -> str:
"""Searches the API for the query."""
return "Results"如果您的函数需要更多结构化参数,您可以StructuredTool直接使用该类,或者仍然继承该类BaseTool。
要从给定函数动态生成结构化工具,最快的入门方法是使用StructuredTool.from_function().
import requests
from langchain.tools import StructuredTool
def post_message(url: str, body: dict, parameters: Optional[dict] = None) -> str:
"""Sends a POST request to the given url with the given body and parameters."""
result = requests.post(url, json=body, params=parameters)
return f"Status: {result.status_code} - {result.text}"
tool = StructuredTool.from_function(post_message)
#BaseTool 自动从 _run 方法的签名中推断模式。
from typing import Optional, Type
from langchain.callbacks.manager import AsyncCallbackManagerForToolRun, CallbackManagerForToolRun
class CustomSearchTool(BaseTool):
name = "custom_search"
description = "useful for when you need to answer questions about current events"
def _run(self, query: str, engine: str = "google", gl: str = "us", hl: str = "en", run_manager: Optional[CallbackManagerForToolRun] = None) -> str:
"""Use the tool."""
search_wrapper = SerpAPIWrapper(params={"engine": engine, "gl": gl, "hl": hl})
return search_wrapper.run(query)
async def _arun(self, query: str, engine: str = "google", gl: str = "us", hl: str = "en", run_manager: Optional[AsyncCallbackManagerForToolRun] = None) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("custom_search does not support async")
# You can provide a custom args schema to add descriptions or custom validation
class SearchSchema(BaseModel):
query: str = Field(description="should be a search query")
engine: str = Field(description="should be a search engine")
gl: str = Field(description="should be a country code")
hl: str = Field(description="should be a language code")
class CustomSearchTool(BaseTool):
name = "custom_search"
description = "useful for when you need to answer questions about current events"
args_schema: Type[SearchSchema] = SearchSchema
def _run(self, query: str, engine: str = "google", gl: str = "us", hl: str = "en", run_manager: Optional[CallbackManagerForToolRun] = None) -> str:
"""Use the tool."""
search_wrapper = SerpAPIWrapper(params={"engine": engine, "gl": gl, "hl": hl})
return search_wrapper.run(query)
async def _arun(self, query: str, engine: str = "google", gl: str = "us", hl: str = "en", run_manager: Optional[AsyncCallbackManagerForToolRun] = None) -> str:
"""Use the tool asynchronously."""
raise NotImplementedError("custom_search does not support async")
#使用装饰器
#tool如果签名有多个参数,装饰器会自动创建一个结构化工具。
import requests
from langchain.tools import tool
@tool
def post_message(url: str, body: dict, parameters: Optional[dict] = None) -> str:
"""Sends a POST request to the given url with the given body and parameters."""
result = requests.post(url, json=body, params=parameters)
return f"Status: {result.status_code} - {result.text}"LangChain支持很多流行的工具,如下图:
In this part of the documentation we cover the different types of agents, disregarding which specific tools they are used with.
For a high level overview of the different types of agents, see the below documentation.
Agent Types (代理类型,例如zero-shot-react-description,react-docstore,self-ask-with-search,conversational-react-description)
For documentation on how to create a custom agent, see the below.
Custom Agent (可以自定义代理)
We also have documentation for an in-depth dive into each agent type.
This section of documentation covers agents with toolkits - eg an agent applied to a particular use case.
See below for a full list of agent toolkits
Agent executors take an agent and tools and use the agent to decide which tools to call and in what order.
In this part of the documentation we cover other related functionality to agent executors
Plan and execute agents accomplish an objective by first planning what to do, then executing the sub tasks. This idea is largely inspired by BabyAGI and then the “Plan-and-Solve” paper.
The planning is almost always done by an LLM.
The execution is usually done by a separate agent (equipped with tools).
from langchain.chat_models import ChatOpenAI
from langchain.experimental.plan_and_execute import PlanAndExecute, load_agent_executor, load_chat_planner
from langchain.llms import OpenAI
from langchain import SerpAPIWrapper
from langchain.agents.tools import Tool
from langchain import LLMMathChain
search = SerpAPIWrapper()
llm = OpenAI(temperature=0)
llm_math_chain = LLMMathChain.from_llm(llm=llm, verbose=True)
tools = [
Tool(
name = "Search",
func=search.run,
description="useful for when you need to answer questions about current events"
),
Tool(
name="Calculator",
func=llm_math_chain.run,
description="useful for when you need to answer questions about math"
),
]
model = ChatOpenAI(temperature=0)
planner = load_chat_planner(model)
executor = load_agent_executor(model, tools, verbose=True)
agent = PlanAndExecute(planner=planner, executor=executor, verbose=True)
agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")LangChain provides a callbacks system that allows you to hook into the various stages of your LLM application. This is useful for logging, monitoring, streaming, and other tasks.
You can subscribe to these events by using the callbacks argument available throughout the API. This argument is list of handler objects, which are expected to implement one or more of the methods described below in more detail. There are two main callbacks mechanisms:
Constructor callbacks will be used for all calls made on that object, and will be scoped to that object only, i.e. if you pass a handler to the LLMChain constructor, it will not be used by the model attached to that chain.
Request callbacks will be used for that specific request only, and all sub-requests that it contains (eg. a call to an LLMChain triggers a call to a Model, which uses the same handler passed through). These are explicitly passed through.
Advanced: When you create a custom chain you can easily set it up to use the same callback system as all the built-in chains. _call, _generate, _run, and equivalent async methods on Chains / LLMs / Chat Models / Agents / Tools now receive a 2nd argument called run_manager which is bound to that run, and contains the logging methods that can be used by that object (i.e. on_llm_new_token). This is useful when constructing a custom chain. See this guide for more information on how to create custom chains and use callbacks inside them.
CallbackHandlers are objects that implement the CallbackHandler interface, which has a method for each event that can be subscribed to. The CallbackManager will call the appropriate method on each handler when the event is triggered.
扫码关注不迷路!!!
郑州升龙商业广场B座25层
service@iqiqiqi.cn

联系电话:187-0363-0315
联系电话:199-3777-5101





