
LlamaIndex 是一个“数据框架”,可帮助您构建 LLM 应用程序。它提供了以下工具:
提供数据连接器以获取您现有的数据源和数据格式(API、PDF、文档、SQL 等)
提供构建数据(索引、图表)的方法,以便这些数据可以轻松地与 LLM 一起使用。
为您的数据提供高级检索/查询界面:输入任何 LLM 输入提示,取回检索到的上下文和知识增强输出。
允许与您的外部应用程序框架轻松集成(例如,与 LangChain、Flask、Docker、ChatGPT 等)。
LlamaIndex 为初学者和高级用户提供工具。我们的高级 API 允许初学者使用LlamaIndex 在 5 行代码中摄取和查询他们的数据。我们的低级 API 允许高级用户自定义和扩展任何模块(数据连接器、索引、检索器、查询引擎、重新排名模块)以满足他们的需求。
LlamaIndex的核心任务是在大型语言模型 (LLM) 和您的私有外部数据之间提供一个接口。在过去的几个月里,它已成为 LLM 数据增强(上下文增强生成)最流行的开源框架之一,适用于各种用例:问答、摘要、结构化查询等。
LlamaIndex 0.6.0 在以下方面进行了一些根本性的更改:
将状态与计算分离:我们将抽象分离,以便更清晰地分离状态(数据 + 索引)与计算(检索器、查询引擎)。
逐步揭示复杂性:我们希望 LlamaIndex 能够同时满足 初学者和高级用户的需求。我们引入了一种新的对开发人员友好的低级 API,它强调可组合性并使界面更加清晰,以便更轻松地实现您的自定义构建块。在这篇博文中,我们将讨论 LlamaIndex 的关键抽象,突出显示 API 更改,并讨论它们背后的动机。
Principled Storage Abstractions:我们重写了我们的存储抽象,使其更加灵活(存储数据和索引)和可扩展(超越内存存储)。
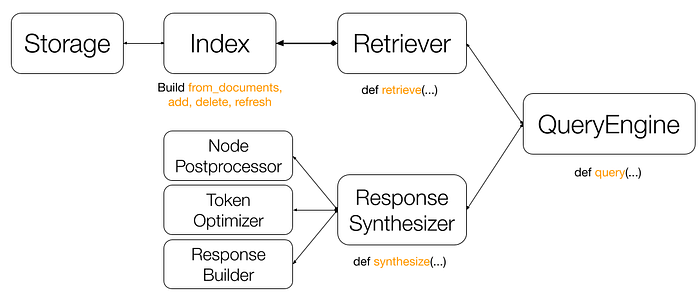
核心组件是:
索引:维护进程文件(即节点)的状态。它也可以理解为数据集合的视图,以及有助于检索和响应合成的有用元数据。
检索器:维护从索引中获取相关节点的逻辑。它通常是为特定索引定义的。
响应合成器:管理计算以生成给定检索到的节点的最终响应。它的核心组件是响应生成器,但可以选择通过其他组件(例如节点后处理器和令牌优化器)进行扩充,以进一步提高检索相关性并降低令牌成本。
查询引擎:将所有内容联系在一起并公开一个干净的查询界面。它可以选择性地通过查询转换和多步推理来增强,以进一步提高查询性能。
index = GPTSimpleVectorIndex.from_documents(documents) # 配置检索器 retriever = VectorIndexRetriever( similarity_top_k= 3 , vector_store_query_mode=VectorStoreQueryMode.HYBRID, alpha= 0.5 , ) # 配置响应合成器 synth = ResponseSynthesizer.from_args( response_mode= 'tree_summarize' , node_postprocessors=[ 关键字节点后处理器(required_keywords=[ 'llama' ]), ], optimizer=SentenceEmbeddingOptimizer(threshold_cutoff= 0.5 ), ) # 构建查询引擎 query_engine = RetrieverQueryEngine( retriever=retriever, response_synthesizer=synth, ) query_engine.query( "谁是 Paul Graham?" )
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
index.storage_context.persist() #保存索引到磁盘里面
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# load index
index = load_index_from_storage(storage_context) #从磁盘加载索引使用日志
import logging import sys logging.basicConfig(stream=sys.stdout, level=logging.DEBUG) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
第一步是加载数据。此数据以对象的形式表示Document。我们提供了多种数据加载器,通过函数加载到Documents中load_data,例如:
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader('data').load_data()
#您也可以选择手动构建文档。LlamaIndex 公开了该Document结构。
from llama_index import Document
text_list = [text1, text2, ...]
documents = [Document(t) for t in text_list]Document 代表围绕数据源的轻量级容器。您现在可以选择继续执行以下步骤之一:
将 Document 对象直接送入索引(参见第 3 节)。
首先将 Document 转换为 Node 对象(参见第 2 节)。
下一步是将这些 Document 对象解析为 Node 对象。节点代表源文档的“块”,无论是文本块、图像还是更多。它们还包含元数据以及与其他节点和索引结构的关系信息。
节点是 LlamaIndex 中的一等公民。您可以选择直接定义节点及其所有属性。您也可以选择通过我们的NodeParser类将源文档“解析”为节点。
例如,你可以做
from llama_index.node_parser import SimpleNodeParser parser = SimpleNodeParser() nodes = parser.get_nodes_from_documents(documents) #您也可以选择手动构建 Node 对象并跳过第一部分。例如 from llama_index.data_structs.node import Node, DocumentRelationship node1 = Node(text="<text_chunk>", doc_id="<node_id>") node2 = Node(text="<text_chunk>", doc_id="<node_id>") # set relationships node1.relationships[DocumentRelationship.NEXT] = node2.get_doc_id() node2.relationships[DocumentRelationship.PREVIOUS] = node1.get_doc_id() nodes = [node1, node2]
我们现在可以为这些 Document 对象建立索引。最简单的高级抽象是在索引初始化期间加载 Document 对象(如果您直接来自第 1 步并跳过第 2 步,这就是相关的)。
from llama_index import GPTVectorStoreIndex index = GPTVectorStoreIndex.from_documents(documents) # 您还可以选择直接在一组 Node 对象上构建索引(这是步骤 2 的延续)。 from llama_index import GPTVectorStoreIndex index = GPTVectorStoreIndex(nodes) # 根据您使用的索引,LlamaIndex 可能会调用 LLM 来构建索引 ''' 跨索引结构重用节点 如果您定义了多个 Node 对象,并希望在多个索引结构中共享这些 Node 对象, 您可以这样做。只需实例化一个 StorageContext 对象, 将 Node 对象添加到基础 DocumentStore,然后传递 StorageContext。 ''' from llama_index import StorageContext storage_context = StorageContext.from_defaults() storage_context.docstore.add_documents(nodes) index1 = GPTVectorStoreIndex(nodes, storage_context=storage_context) index2 = GPTListIndex(nodes, storage_context=storage_context)
您可以在其他索引之上构建索引!可组合性使您能够更强大地索引异构数据源。有关相关用例的讨论,请参阅我们的查询用例。有关技术细节和示例,请参阅我们的可组合性操作指南。
建立索引后,您现在可以使用QueryEngine. 请注意,“查询”只是 LLM 的输入——这意味着您可以使用索引来回答问题,但您还可以做更多的事情!
#首先,您可以使用默认值QueryEngine(即使用默认配置)查询索引,如下所示:
query_engine = index.as_query_engine()
response = query_engine.query("What did the author do growing up?")
print(response)
response = query_engine.query("Write an email to the user given their background information.")
print(response)#我们还支持低级组合 API,让您可以更精细地控制查询逻辑。下面我们重点介绍一些可能的自定义设置。
from llama_index import (
GPTVectorStoreIndex,
ResponseSynthesizer,
)
from llama_index.retrievers import VectorIndexRetriever
from llama_index.query_engine import RetrieverQueryEngine
from llama_index.indices.postprocessor import SimilarityPostprocessor
# build index
index = GPTVectorStoreIndex.from_documents(documents)
# configure retriever
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=2,
)
# configure response synthesizer
response_synthesizer = ResponseSynthesizer.from_args(
node_postprocessors=[
SimilarityPostprocessor(similarity_cutoff=0.7)
]
)
# assemble query engine
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
)
# query
response = query_engine.query("What did the author do growing up?")
print(response)
# 解析响应
# 返回的对象是一个Response对象。该对象包含响应文本以及响应的“来源”:
response = query_engine.query("<query_str>")
# get response
# response.response
str(response)
# get sources
response.source_nodes
# formatted sources
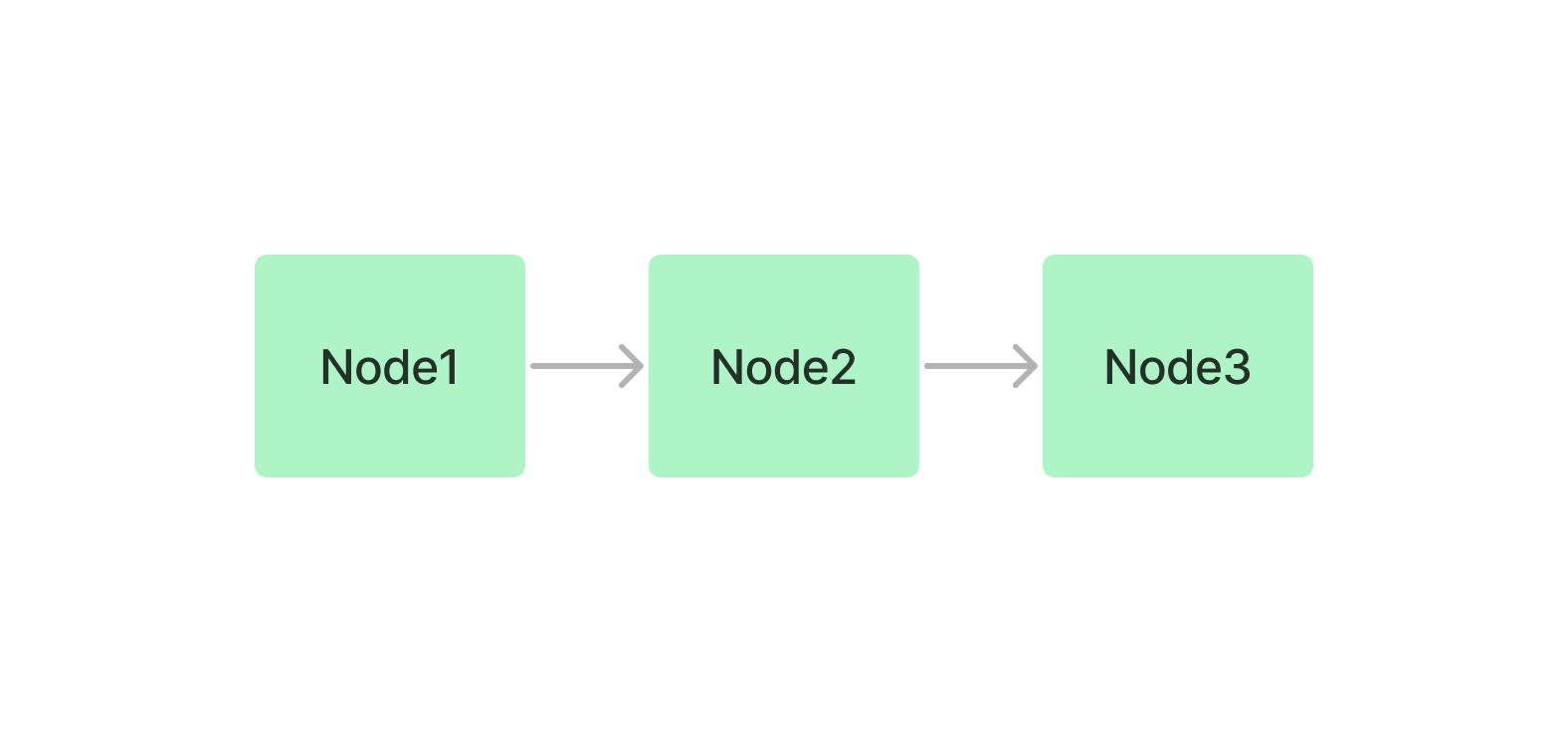
response.get_formatted_sources()列表索引只是将节点存储为顺序链。
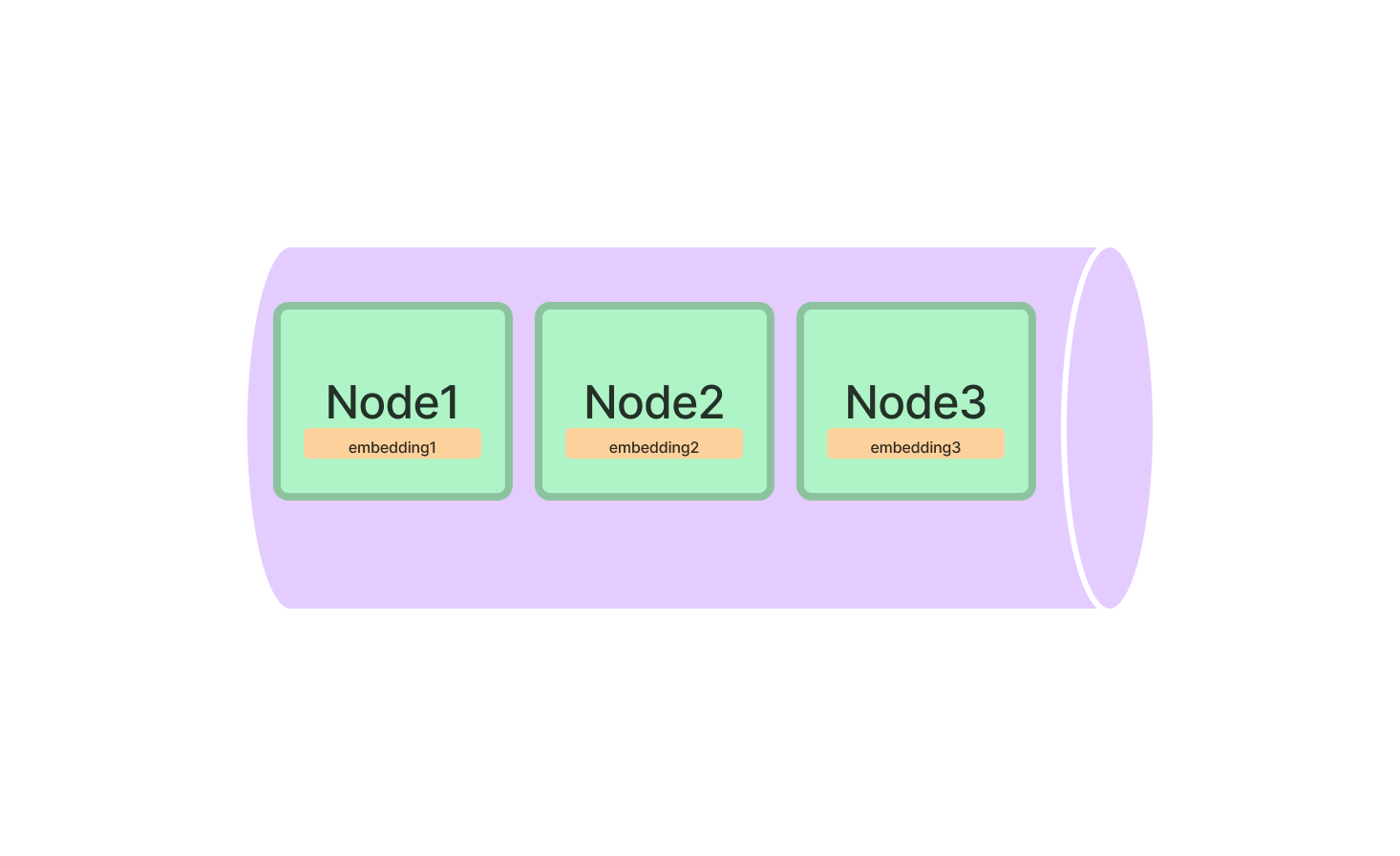
向量存储索引存储每个节点和向量存储中的相应嵌入。
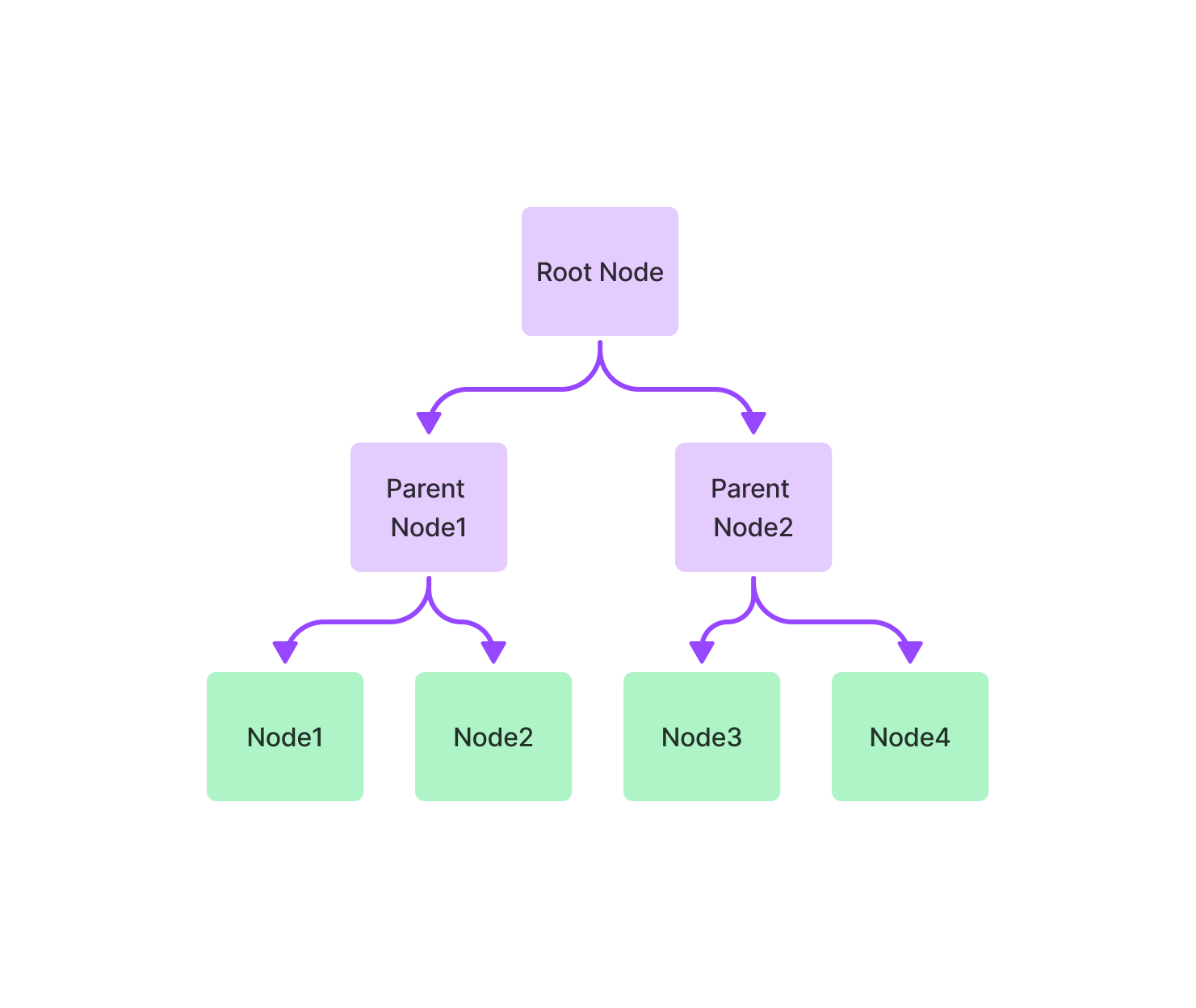
树索引从一组节点(成为这棵树中的叶节点)构建一个层次树。
关键字表索引从每个节点中提取关键字,并构建从每个关键字到该关键字对应节点的映射。
LlamaIndex 最基本的示例用法是通过语义搜索。我们提供了一个简单的内存矢量存储供您入门,但您也可以选择使用我们的任何一个矢量存储集成:
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader documents = SimpleDirectoryReader('data').load_data() index = GPTVectorStoreIndex.from_documents(documents) query_engine = index.as_query_engine() response = query_engine.query("What did the author do growing up?") print(response)
相关资源:
摘要查询要求 LLM 遍历许多(如果不是大多数)文档以综合答案。例如,汇总查询可能如下所示:
“这个文本集的摘要是什么?”
“给我总结一下 X 人在公司的经历。”
通常,列表索引适合这种用例。默认情况下,列表索引遍历所有数据。
根据经验,设置response_mode="tree_summarize"也会导致更好的摘要结果。
index = GPTListIndex.from_documents(documents) query_engine = index.as_query_engine( response_mode="tree_summarize" ) response = query_engine.query("<summarization_query>")
LlamaIndex 支持对结构化数据的查询,无论是 Pandas DataFrame 还是 SQL 数据库。
以下是一些相关资源:
导游
例子
LlamaIndex 支持跨异构数据源进行综合。这可以通过在现有数据上绘制图表来完成。具体来说,在您的子索引上创建一个列表索引。列表索引固有地结合了每个节点的信息;因此它可以跨异构数据源综合信息。
from llama_index import GPTVectorStoreIndex, GPTListIndex from llama_index.indices.composability import ComposableGraph index1 = GPTVectorStoreIndex.from_documents(notion_docs) index2 = GPTVectorStoreIndex.from_documents(slack_docs) graph = ComposableGraph.from_indices(GPTListIndex, [index1, index2], index_summaries=["summary1", "summary2"]) query_engine = graph.as_query_engine() response = query_engine.query("<query_str>")
以下是一些相关资源:
LlamaIndex 还支持通过异构数据源进行路由RouterQueryEngine——例如,如果您想将查询“路由”到基础文档或子索引。
为此,首先在不同的数据源上构建子索引。然后构造相应的查询引擎,给每个查询引擎一个描述,得到一个QueryEngineTool.
from llama_index import GPTTreeIndex, GPTVectorStoreIndex from llama_index.tools import QueryEngineTool ... # define sub-indices index1 = GPTVectorStoreIndex.from_documents(notion_docs) index2 = GPTVectorStoreIndex.from_documents(slack_docs) # define query engines and tools tool1 = QueryEngineTool.from_defaults( query_engine=index1.as_query_engine(), description="Use this query engine to do...", ) tool2 = QueryEngineTool.from_defaults( query_engine=index2.as_query_engine(), description="Use this query engine for something else...", )
然后,我们RouterQueryEngine在它们之上定义一个。默认情况下,这使用 aLLMSingleSelector作为路由器,根据描述,它使用 LLM 选择最佳子索引以将查询路由到。
from llama_index.query_engine import RouterQueryEngine query_engine = RouterQueryEngine.from_defaults( query_engine_tools=[tool1, tool2] ) response = query_engine.query( "In Notion, give me a summary of the product roadmap." )
以下是一些相关资源:
LlamaIndex 也可以支持比较/对比查询。它可以通过以下方式执行此操作:
根据您的数据绘制图表
添加查询转换。
您只需在数据上绘制图表即可执行比较/对比查询。
以下是一些相关资源:
您还可以使用查询转换模块执行比较/对比查询。
from llama_index.indices.query.query_transform.base import DecomposeQueryTransform decompose_transform = DecomposeQueryTransform( llm_predictor_chatgpt, verbose=True )
该模块将帮助您在现有索引结构上将复杂的查询分解为更简单的查询。
以下是一些相关资源:
LlamaIndex 还可以支持多步查询。给定一个复杂的查询,将其分解为子问题。
例如,给定一个问题“作者启动的第一批加速器程序是谁?”,该模块首先将查询分解为一个更简单的初始问题“作者启动的加速器程序是什么?”,查询索引,然后提出后续问题。
以下是一些相关资源:
扫码关注不迷路!!!
郑州升龙商业广场B座25层
service@iqiqiqi.cn

联系电话:187-0363-0315
联系电话:199-3777-5101





